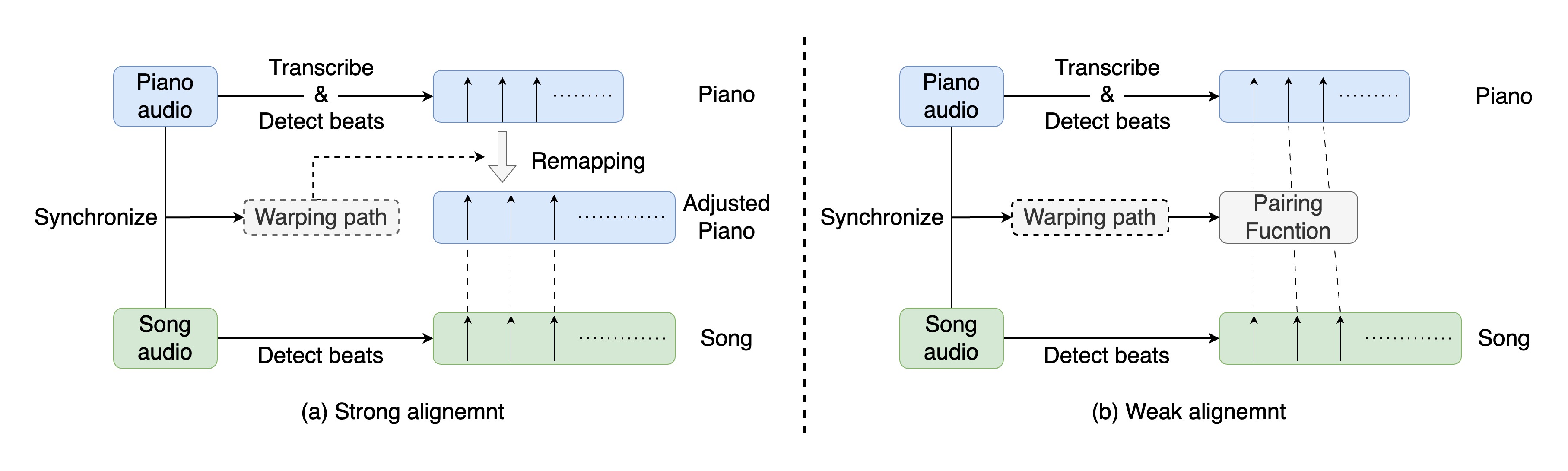
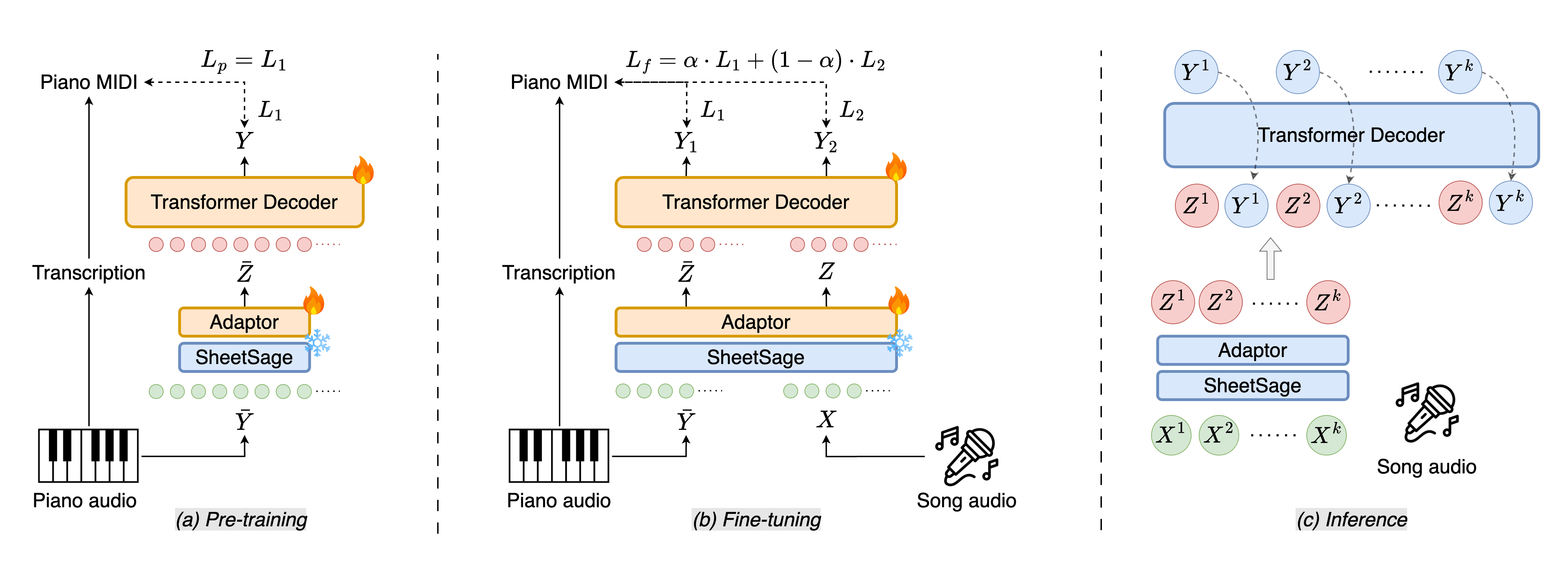
Piano cover generation aims to create a piano cover from a pop song. Existing approaches mainly employ supervised learning and the training demands strongly-aligned and paired song-to-piano data, which is built by remapping piano notes to song audio. This would, however, result in the loss of piano information and accordingly cause inconsistencies between the original and remapped piano versions. To overcome this limitation, we propose a transfer learning approach that pre-trains our model on piano-only data and fine-tunes it on weakly-aligned paired data constructed without note remapping. During pre-training, to guide the model to learn piano composition concepts instead of merely transcribing audio, we use an existing lead sheet transcription model as the encoder to extract high-level features from the piano recordings. The pre-trained model is then fine-tuned on the paired song-piano data to transfer the learned composition knowledge to the pop song domain. Our evaluation shows that this training strategy enables our model, named PiCoGen2, to attain high-quality results, outperforming baselines on both objective and subjective metrics across five pop genres.
@inproceedings{tan2024picogen2,
author = {Tan, Chih-Pin and Ai, Hsin and Chang, Yi-Hsin and Guan, Shuen-Huei and Yang, Yi-Hsuan},
title = {PiCoGen2: Piano cover generation with transfer learning approach and weakly aligned data},
year = 2024,
month = nov,
booktitle = {Proceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR)},
address = {San Francisco, CA, United States},
}